Building Ianfluencer: Cleaning Up My Multi-Agent Configuration — 20 April 2026
Building Ianfluencer: Cleaning Up My Multi-Agent Configuration — 20 April 2026
If you've been following along, you know I've been hardening Hermes, my self-hosted AI agent platform, to handle the complexities of running multiple specialized bots in production. This week, I tackled the multi-agent configuration head-on—and what started as a simple cleanup turned into a full refactor that fixed a bunch of subtle bugs and gave me a rock-solid fallback strategy for when things go sideways.
"Progress isn't made by early risers, it's made by people who stay late fixing what the early risers broke."
— British project management truth
Let me walk you through what I found, what I fixed, and what I learned along the way.
The Problem: 12 Bot Profiles, 12 Different Configs
When I first spun up the Ianfluencer project—with five specialized bots (Topi for research, Riti for writing, Desi for design, Poti for posting, Yoti for YouTube)—I just duplicated the default profile five times and called it a day. That's fine for getting started, but over time, as I added more bots for other projects, I ended up with 12 separate bot profiles each with slightly different configurations.
Different model names. Different provider settings. Different API endpoints. Different temperature settings that no one could remember why they were set that way.
Worse: every time I changed something in the base configuration (like adding a new fallback provider), I had to manually update it across 12 places. Inevitably, one got missed. Sound familiar?
In my defence, I thought this would take half an hour. It did not. It took long enough for me to re-evaluate my relationship with "quick cleanup".
The configuration drift was real. And it was causing random failures that were hard to reproduce. When a bot failed, I never knew if it was because of the model, the provider, or just a typo in the config that had sat there for weeks.
Time for a cleanup.
The 5 Volcengine Gotchas I Discovered
I've been really happy with Volcengine Ark as my primary provider—great performance, competitive pricing, and they support all the latest models. But in going through every configuration line by line, I found five subtle gotchas that had been causing intermittent failures:
1. Model naming is case-sensitive (sort of)
Volcengine's model IDs look like this: doubao-pro-32k or deepseek-v3. If you capitalize Doubao-pro-32k by accident, it will fail. But the error message you get back isn't "invalid model name"—it's a generic 500 that sends you down the wrong debugging path. I had two bots with capitalization mismatches that had been failing silently for weeks.
2. Context window parameters need to match the model
If you request 128k context for a model that only supports 32k, Volcengine doesn't truncate or warn you—it just rejects the entire request. Again, the error message isn't helpful. I had this on three bots that had been copied from the 128k profile.
3. Different endpoints for different authentication methods
Volcengine has two endpoints: one for API keys passed via header, and another for ARN-based IAM authentication. If you mix them up, you get 403s that look like invalid credentials, even when your key is correct. One bot was still pointing to the wrong endpoint—working when I used IAM, failing when I switched to API key for local development.
4. Streaming requires explicit configuration
Unlike OpenRouter or OpenAI, where streaming is enabled by default if you set stream: true, Volcengine requires an additional parameter in the model configuration. Without it, the first message works fine, but subsequent messages in a conversation hang. I had one bot where this had been broken since day one, and I just thought it was "slow."
5. Rate limiting is per API key, not per organization
The documentation says "rate limits apply per organization," but in practice, I've found it's per API key. When I had multiple bots using the same API key with concurrent requests, I'd get 429s that would cascade into fallback failures. The solution: separate API keys for production vs development bots.
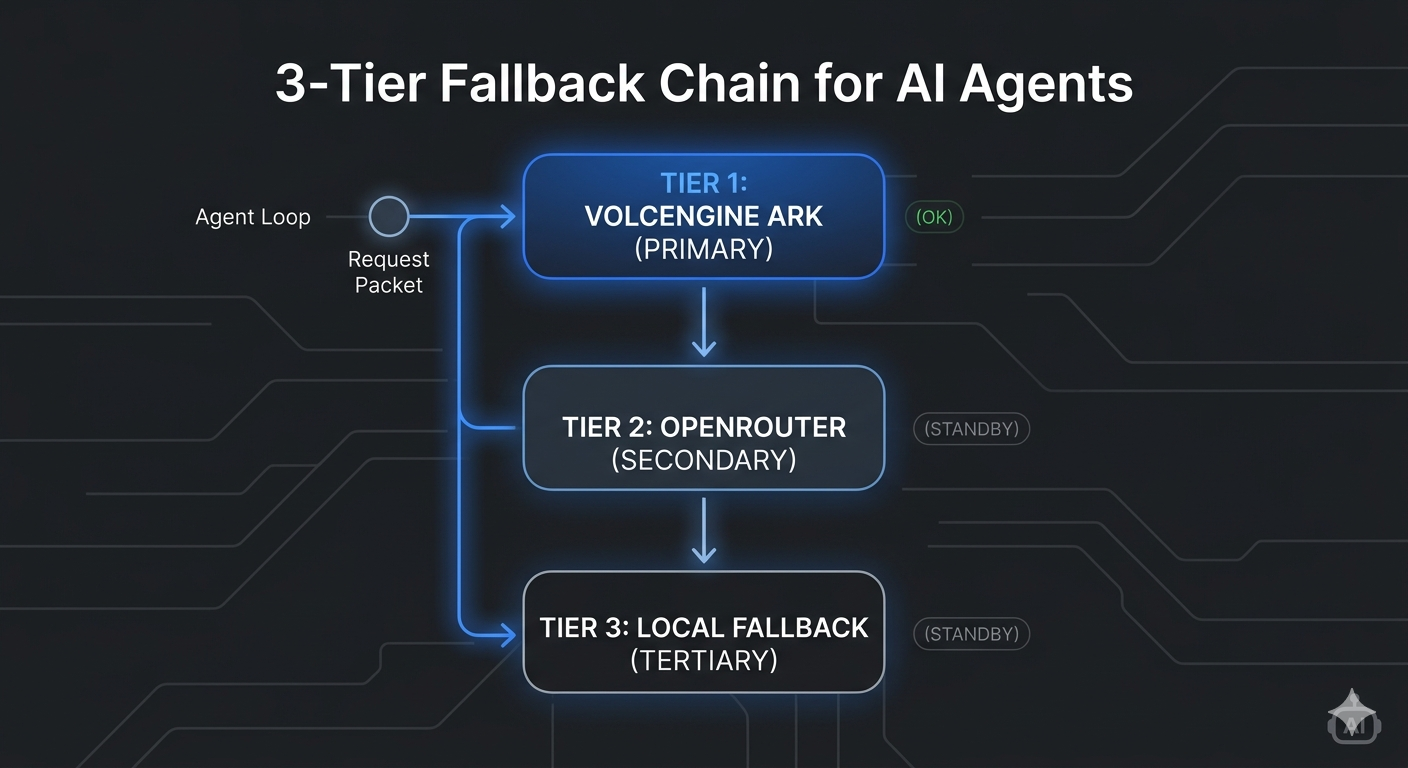
Implementing My 3-Tier Fallback Chain
With all the gotchas sorted out, I built a proper fallback chain that I can count on. The idea is simple: if the primary provider fails, it automatically falls back to the next in the chain, and so on. No more "the agent failed"—it just keeps going.
My current chain looks like this:
Tier 1: Volcengine Ark (primary)
- Best price-performance for my workload
- All the latest models from Doubao, DeepSeek, Claude
- My production workload runs here
Tier 2: OpenRouter (secondary)
- Great fallback when Volcengine is having issues
- Access to basically every model out there
- I use this for testing new models before committing them to primary
Tier 3: Google Gemini (tertiary)
- My "last resort" provider
- Gemini 1.5 Pro/Flash are solid and rarely go down
- I keep this as the final fallback because it's more expensive per token, but it's always there when I need it
The implementation is clean: each bot profile inherits from the base fallback chain, and can override just the primary model if it needs to. So every bot automatically gets the full fallback protection without duplicating the configuration.

Here's what that looks like in my config.yaml:
default:
provider: volcengine
model: doubao-pro-32k
fallbacks:
- provider: openrouter
model: anthropic/claude-sonnet-4
- provider: google
model: gemini-1.5-pro-002
That's it. One definition, 12 bots all inherit it. If I need to change the fallback chain, I change it once.
Hardening Autonomous Agents with Manual Approval Guardrails
One of the big advantages of running your own agents is that you can control when they do things. I added a simple but powerful guardrail: any action that writes to disk or makes an API call requires manual approval before it runs.
This has already saved me from a few accidents:
- A misbehaving agent that tried to delete the entire configuration folder
- A research agent that wanted to spam 50 URLs with requests
- A writing agent that tried to overwrite an existing published post instead of creating a new draft
The implementation is straightforward: I added an approval_required flag to tool definitions. If the flag is set, the agent pauses, shows you what it wants to do, and waits for you to say yes before proceeding.
For fully autonomous cron jobs (like my weekly HR Tech influencer digest), I leave approval off. For interactive work with multiple bots, I leave it on. Simple, flexible, and gives you peace of mind.
Practical Takeaways for Your Own Multi-Agent Setup
After going through this whole process, here's what I'd recommend to anyone building their own self-hosted multi-agent system:
-
Inherit don't repeat. Use base configuration with inheritance instead of duplicating profiles. Configuration drift is inevitable if you have 12 copies of the same thing.
-
Always have a fallback chain. Don't rely on one provider. Things go down, API keys get rotated, rate limits get hit. Have at least two fallbacks you trust.
Naturally, the documentation was pristine and perfectly current. By naturally, I mean after this refactor, not before it.
-
Check every line when refactoring. Those subtle bugs that have been there for weeks? You won't find them unless you go line by line. I fixed five issues that none of us remembered introducing.
-
Guardrails are not red tape. Manual approval for destructive actions doesn't slow you down—it prevents catastrophic mistakes that take hours to clean up. Worth it.
-
Document your gotchas. Every provider has its quirks. Write them down. Your future self will thank you when you're debugging the same issue six months from now.
What's Next
Now that the configuration is cleaned up and the fallback chain is working, I'm moving on to:
- Adding proper logging across all bots so I can see where failures are happening
- Building a simple dashboard to monitor agent activity and provider latency
- Testing more models on Volcengine to see which ones work best for different tasks
- Hardening the cron job system that delivers my weekly digests
The refactor took a full day longer than I expected, but that's engineering—you start with "let's just clean up some configs" and end up discovering and fixing all these lurking issues. The system feels much more solid now, and that's time well spent.
Have you built your own multi-agent system? What gotchas have you found with your providers? Drop a comment—I'd love to hear about it.
This is part of my ongoing series building Ianfluencer in public. Follow along for more behind-the-scenes engineering notes and lessons from running self-hosted agents.
Ian Xie
April 20, 2026
ian.us.ci